嵌入式
utf8
开源
自动生成
Gorm
点图层
免责声明
位置式PID
计算机毕业设计选题
通识
katz中心性
shiro
个人开发
可视化
非线性函数拟合
地图模拟数据
Unity项目清理
效率提升
车辆监测
坐标文件
CLIP
2024/4/11 16:19:02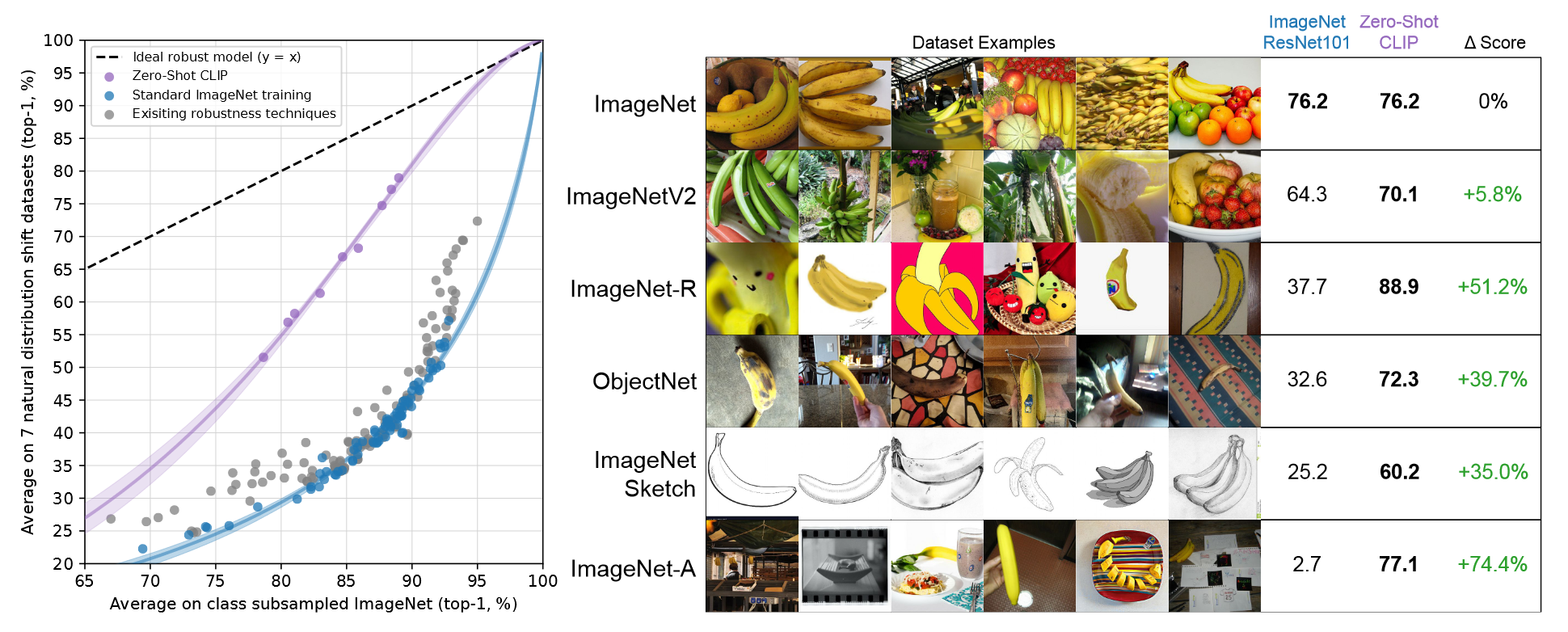
【论文精读】Learning Transferable Visual Models From Natural Language Supervision
Learning Transferable Visual Models From Natural Language Supervision 前言Abstract1. Introduction and Motivating Work2. Approach2.1. Creating a Sufficiently Large Dataset2.2. Selecting an Efficient Pre-Training Method2.3. Choosing and Scaling a Model2.4. P…

【CLIP速读篇】Contrastive Language-Image Pretraining
【CLIP速读篇】Contrastive Language-Image Pretraining 0、前言Abstract1. Introduction and Motivating Work2. Approach2.1. Natural Language Supervision2.2. Creating a Sufficiently Large Dataset2.3. Selecting an Efficient Pre-Training Method2.4. Choosing and Sc…
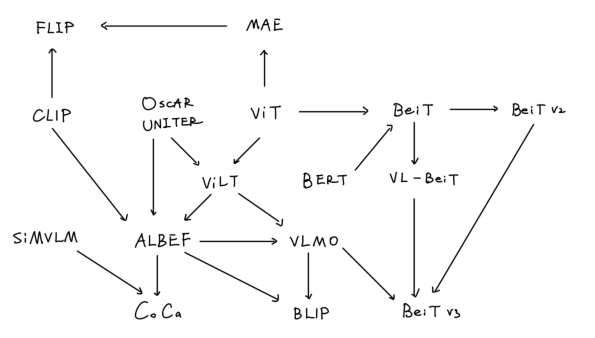
【学习笔记】多模态综述
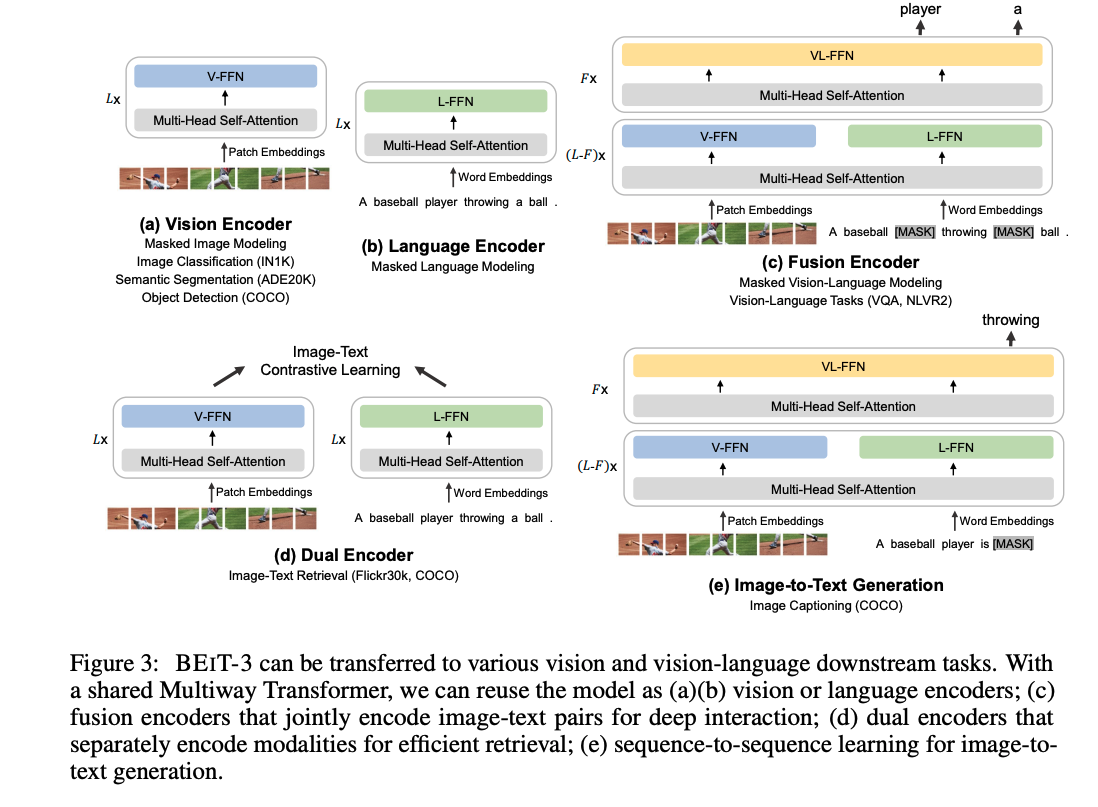
多模态综述 前言1. CLIP & ViLT2. ALBEF3. VLMO4. BLIP5. CoCa6. BeiTv3总结参考链接 前言
本篇学习笔记虽然是多模态综述,本质上是对ViLT后多模态模型的总结,时间线为2021年至2022年,在这两年,多模态领域的模型也是卷的飞起…


首个大规模图文多模态数据集LAION-400M介绍
前言
openAI的图文多模态模型CLIP证明了图文多模态在多个领域都具有着巨大潜力,随之而来掀起了一股图文对比学习的风潮。
就在前几天(2022年12月),连Kaiming都入手这一领域,将MAE的思路与CLIP的思路结合,…
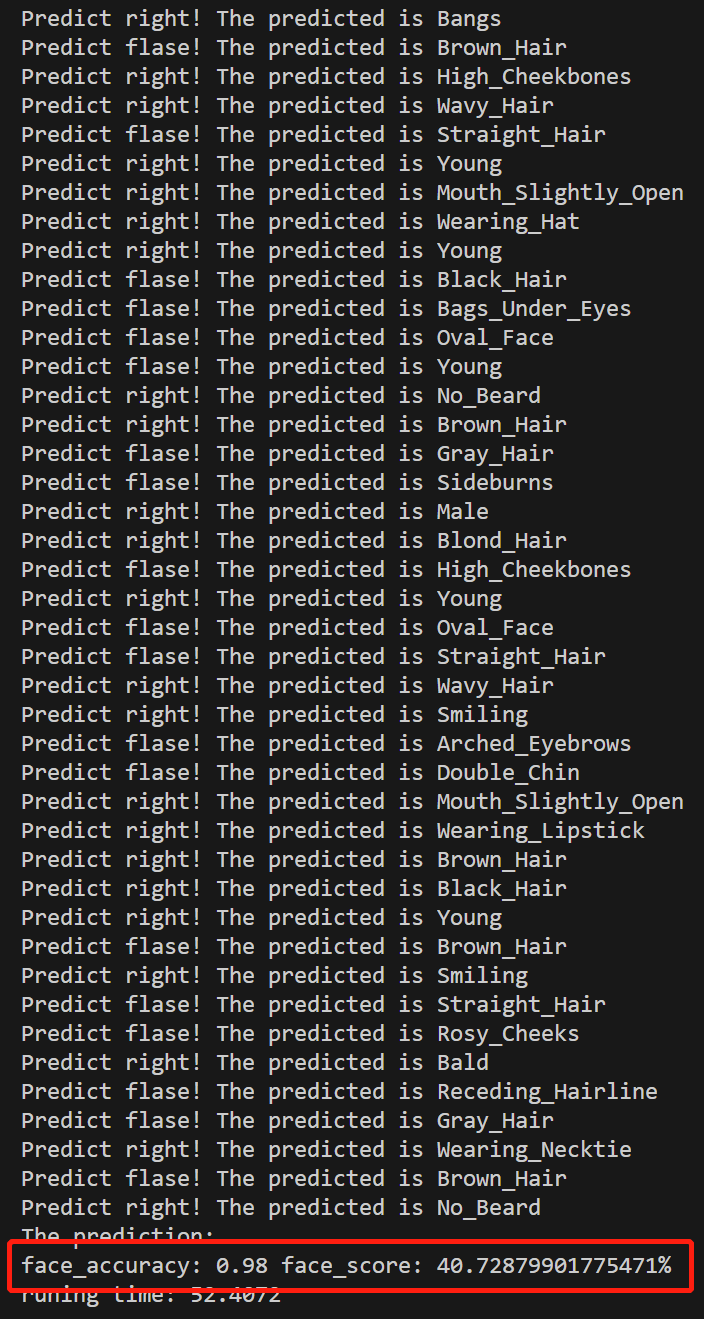
【计算机视觉】如何利用 CLIP 做简单的人脸任务?(含源代码)
文章目录 一、数据集介绍二、源代码 结果三、代码逐行解读 一、数据集介绍
CELEBA 数据集(CelebFaces Attributes Dataset)是一个大规模的人脸图像数据集,旨在用于训练和评估人脸相关的计算机视觉模型。该数据集由众多名人的脸部图像组成&a…
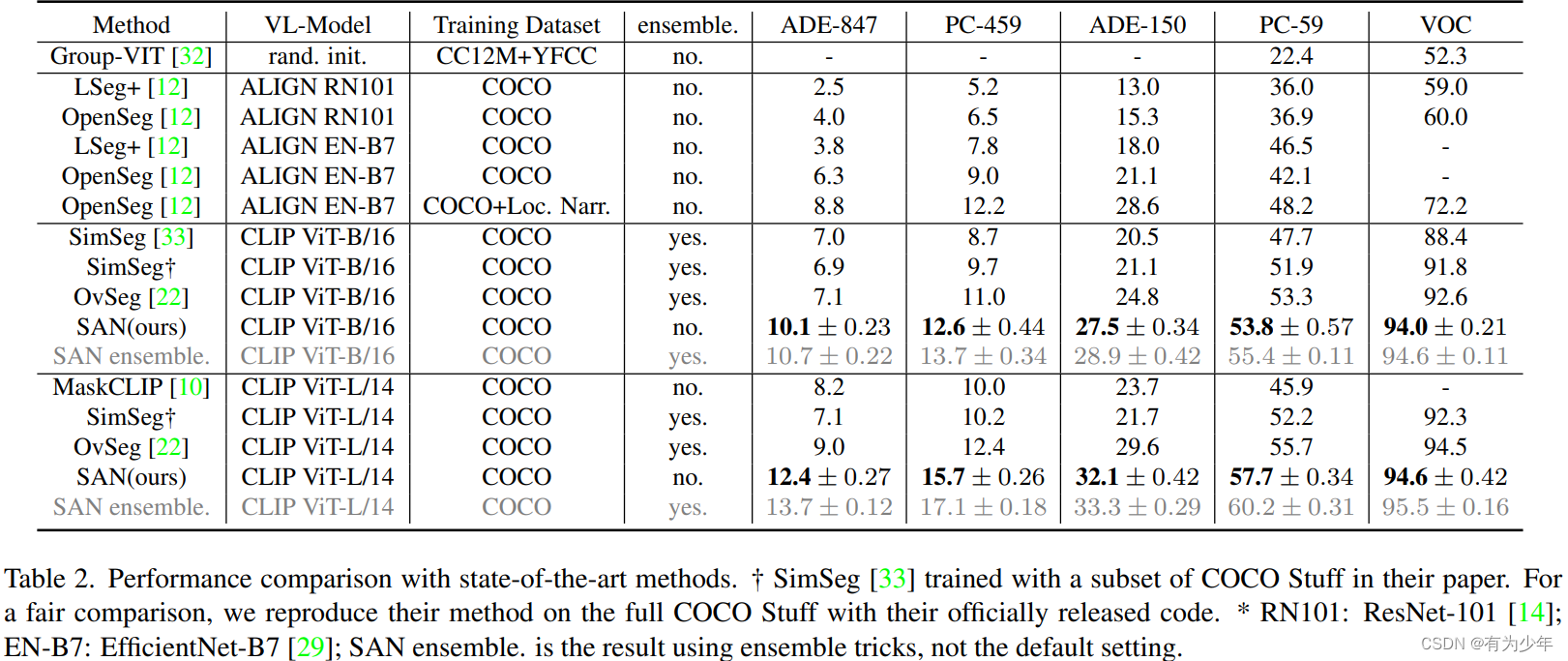
CVPR 2023 | SAN: Side Adapter Network for Open-Vocabulary Semantic Segmentation
CVPR 2023 | SAN: Side Adapter Network for Open-Vocabulary Semantic Segmentation
论文:https://arxiv.org/abs/2302.12242代码:https://github.com/MendelXu/SAN 架构设计
冻结的 CLIP,其位置编码为了适应不同于预训练的输入分辨率&…
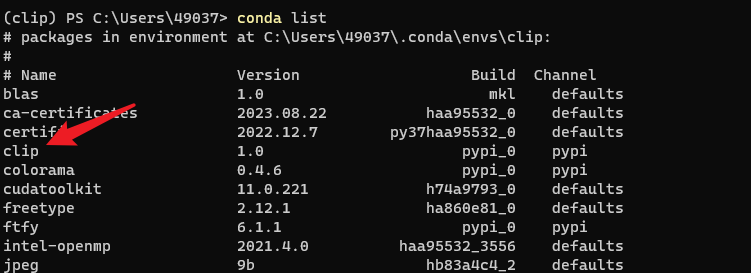
clip代码安装实操
CLIP模型及代码地址:GitHub - openai/CLIP: Contrastive Language-Image Pretraining
代码准备环境
先创建一个anaconda虚拟环境,包含python3.7版本,将该环境命名为clip。成功。
( pytorch1.7.1 所需 python 版本 >3.6&…

ViT-L-14.pt下载load checkpoint from xxx
load checkpoint from E:\BaiduNetdiskDownload\sd-webui-aki-v4\models\BLIP\model_base_caption_capfilt_large.pth stable diffusion反推提示词出现此提示时,需安装以下模型至sd-webui-aki-v4.cache\clip\目录 ViT-L-14.pt
https://openaipublic.azureedge.net/…
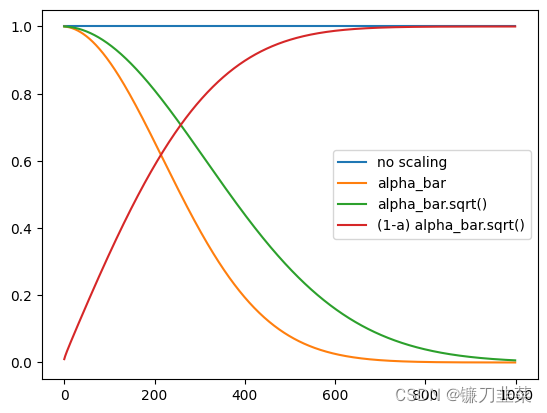
【扩散模型】理解扩散模型的微调(Fine-tuning)和引导(Guidance)
理解扩散模型的微调Fine-tuning和引导Guidance 1. 环境准备2. 加载预训练过的管线3. DDIM——更快的采样过程4. 微调5. 引导6. CLIP引导参考资料 微调(Fine-tuning)指的是在预先训练好的模型上进行进一步训练,以适应特定任务或领域的过程。这…
基于CLIP4Clip的DRL的WTI模块实现
关于DRL的WTI模块:
Weighted Token-wise Interaction: 直觉上,并非所有的单词和视频帧都同等重要。我们提供一种自适应方法,来调整每个标记的权重大小: 注:其中两个f函数都是MLP和softmax构成。
WTI的算…
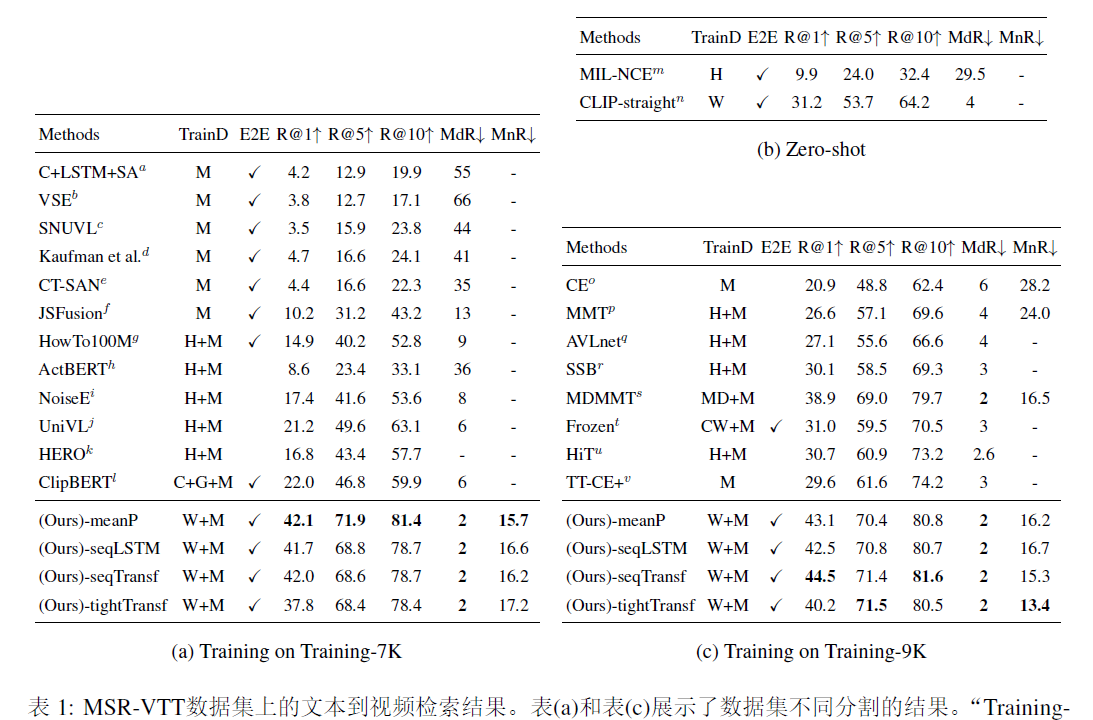
clip4clip:an empirical study of clip for end to end video clip retrieval
广告深度学习计算:阿里妈妈智能创意服务优化使用CPU/GPU分离的多进程架构,加速阿里妈妈智能创意服务。https://mp.weixin.qq.com/s/_pjhXrUZVzFRtiwG2LhnkwCLIP4Clip: CLIP 再下一城,利用CLIP实现视频检索 - 知乎前言: OpenAI 的论…
AI绘画中CLIP文本-图像预训练模型
介绍
OpenAI 在 2021 年提出了 CLIP(Contrastive Language–Image Pretraining)算法,这是一个先进的机器学习模型,旨在理解和解释图像和文本之间的关系。CLIP 的核心思想是通过大规模的图像和文本对进行训练,学习图像…

使用CLIP和LLM构建多模态RAG系统
在本文中我们将探讨使用开源大型语言多模态模型(Large Language Multi-Modal)构建检索增强生成(RAG)系统。本文的重点是在不依赖LangChain或LLlama index的情况下实现这一目标,这样可以避免更多的框架依赖。
什么是RAG
在人工智能领域,检索增强生成(re…

clip属性参数详解
前面说到图片裁剪主要用到clip属性,是css的clip不是canvas的clip(),这里详细说一下参数的意义
w3c是这么介绍的
设置元素的形状。唯一合法的形状值是
clip : rect (top, right, bottom, left)
它是一个css属性,用来进行矩形裁剪,通…

conda环境module ‘clip‘ has no attribute ‘load‘解决
1 问题描述 运行基于clip的zero-shot预测代码,报错如下:
Traceback (most recent call last):File "D:\code\ptcontainer\clip\clipembeding.py", line 38, in <module>clip_embeding ClipEmbeding()File "D:\code\ptcontainer\c…

CLIP:用文本作为监督信号训练可迁移的视觉模型
Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning. PMLR, 2021: 8748-8763. CLIP 是 OpenAI 在 2021 年初的工作,文章发表在 ICML-2021࿰…
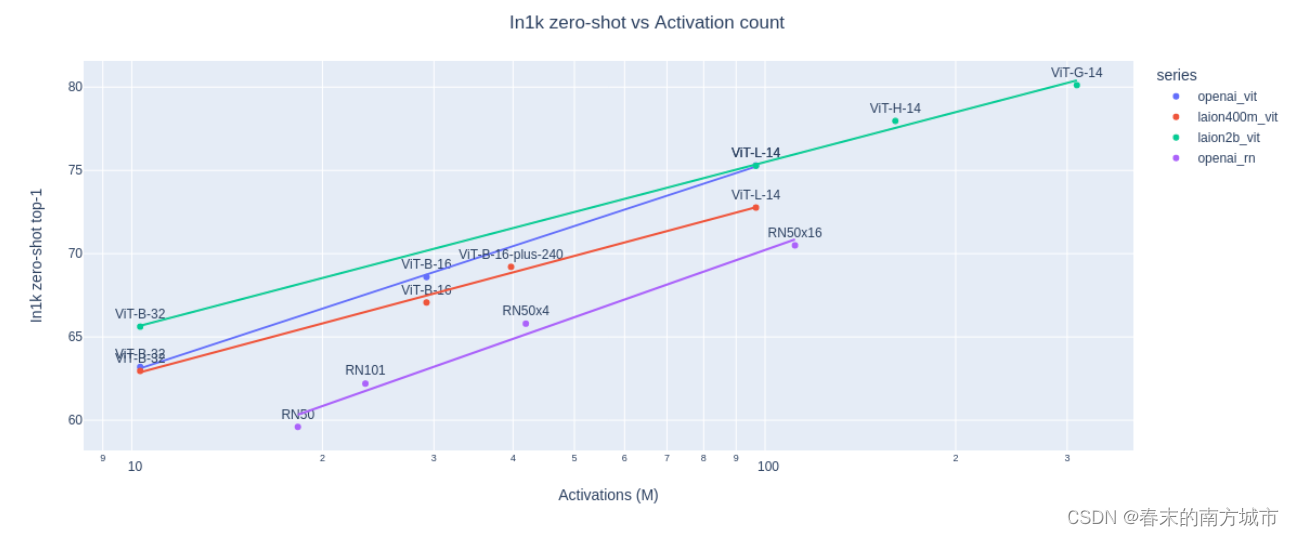
AIGC系列之:CLIP和OpenCLIP
目录
模型背景
CLIP模型介绍
相关资料
原理和方法
Image Encoder
Text Encoder
对比学习
预训练
Zero Shot预测
优势和劣势
总结
OpenClip模型介绍
相关资料
原理
结果
用法
模型总结 模型背景
Stable Diffusion主要由三个核心模块组成: Text Enc…

【EAI 015】CLIPort: What and Where Pathways for Robotic Manipulation
论文标题:CLIPort: What and Where Pathways for Robotic Manipulation 论文作者:Mohit Shridhar1, Lucas Manuelli, Dieter Fox1 作者单位:University of Washington, NVIDIA 论文原文:https://arxiv.org/abs/2109.12098 论文出处…
【多模态】26、视觉-文本多模态任务超详细介绍 「CLIP/LSeg/ViLD/GLIP/ALBEF/BLIP/CoCa/BEIT」
文章目录 准备知识一、CLIP:不同模态简单对比的方法更适合于图文检索1.1 CLIP 在分割上的改进工作1.1.1 LSeg1.1.2 Group ViT 1.2 CLIP 在目标检测上的改进工作1.2.1 ViLD1.2.2 GLIPv11.2.3 GLIPv2 二、ViLT/ALBEF :多模态融合在 VQA/VR 任务中更重要三、…
多模态对比语言图像预训练CLIP:打破语言与视觉的界限,具备零样本能力
多模态对比语言图像预训练CLIP:打破语言与视觉的界限,具备零样本能力。
一种基于多模态(图像、文本)对比训练的神经网络。它可以在给定图像的情况下,使用自然语言来预测最相关的文本片段,而无需为特定任务进行优化。CLIP的设计类似于GPT-2和GPT-3,具备出色的零射击能力…

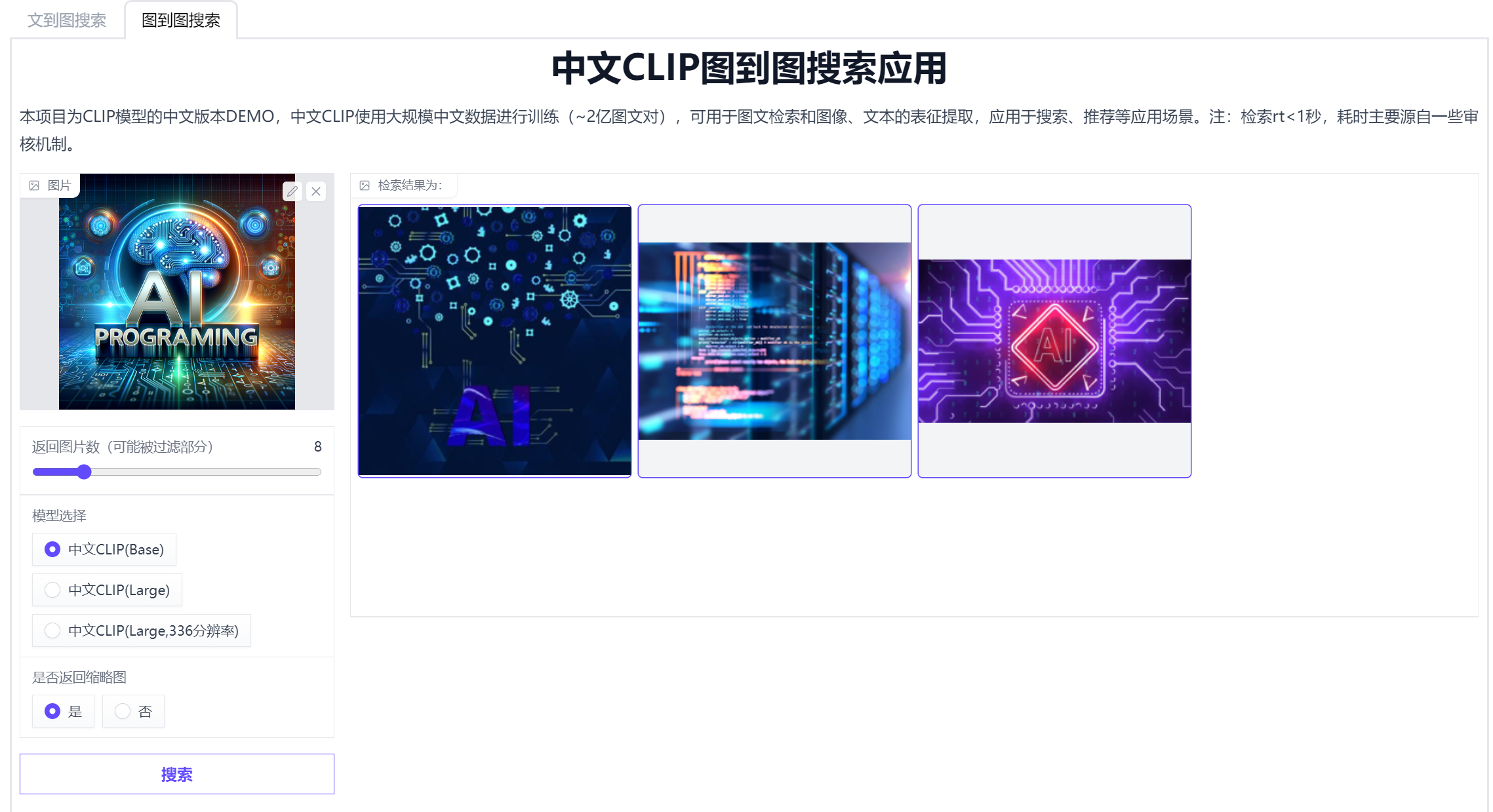
【深度学习】Chinese-CLIP 使用教程,图文检索,跨模态检索,零样本图片分类
代码:https://github.com/OFA-Sys/Chinese-CLIP/blob/master/deployment.md 文章目录 安装环境和onnx推理转换所有模型为onnx测试所有onnx模型的脚本onnx cpu方式执行docker镜像 安装环境和onnx推理
安装环境,下载权重放置到指定目录,进行on…
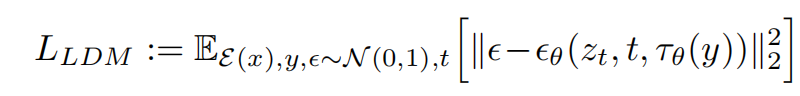
AI绘画Stable Diffusion原理之扩散模型DDPM
前言
传送门: stable diffusion:Git|论文 stable-diffusion-webui:Git Google Colab Notebook部署stable-diffusion-webui:Git kaggle Notebook部署stable-diffusion-webui:Git AI绘画,输入一段…

多模态——旷视大模型Vary更细粒度的视觉感知实现文档级OCR或图表理解
概述
现代大型视觉语言模型(LVLMs),例如CLIP,使用一个共同的视觉词汇,以适应多样的视觉任务。然而,在处理一些需要更精细和密集视觉感知的特殊任务时,例如文档级OCR或图表理解,尤其…
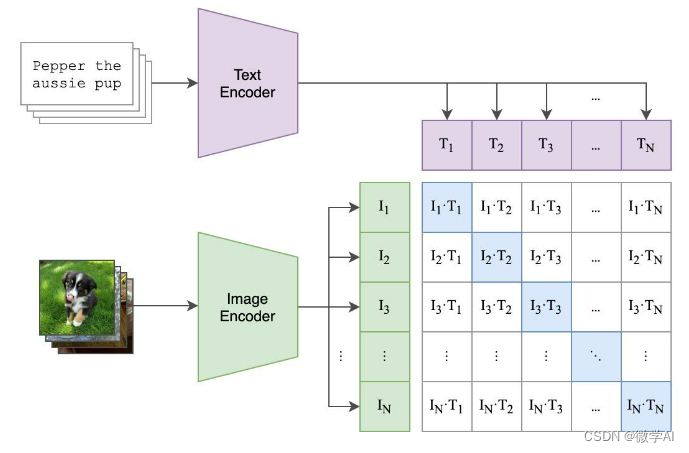
深度学习实战73-基于多模态CLIP模型的实战项目,CLIP模型的架构介绍与代码实现
大家好,我是微学AI,今天给大家介绍一下深度学习实战73-基于多模态CLIP模型的实战项目,CLIP模型的架构介绍与代码实现。多模态CLIP(Contrastive Language-Image Pre-training)模型是一种深度学习模型,其核心设计理念是通过大规模的对比学习训练,实现图像与文本之间的跨模…
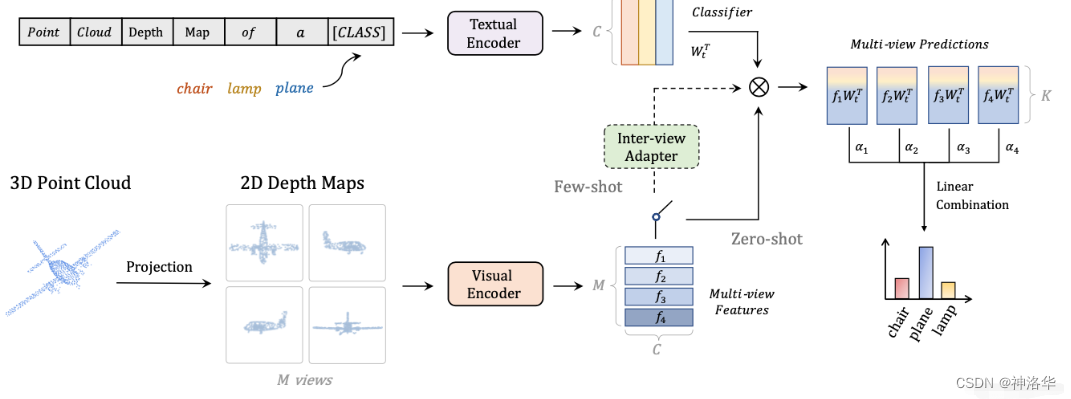
李沐论文精读系列四:CLIP和改进工作串讲(LSeg、GroupViT、VLiD、 GLIPv1、 GLIPv2、CLIPasso)
文章目录一、CLIP1.1 简介1.1.1 前言1.1.2 模型结构1.1.3 模型效果1.1.3.1 对自然分布偏移的鲁棒性1.1.3.2 StyleCLIP1.1.3.3 CLIPDraw1.1.3.4 zero-shot检测1.1.3.5 CLIP视频检索1.1.4 导言1.2 方法1.2.1 自然语言监督的优势1.2.2 预训练方法(训练效率至关重要&…

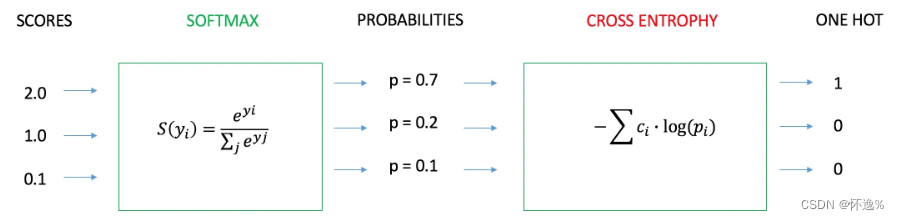
大模型理解之CLIP
前言
2021年2月份,CLIP模型被提出,想法很简单,性能高效,而且具备很好的泛化性。我在这里简单谈论下我对CLIP模型的理解,以及发现的一些问题。
我是在沐神的视频中了解的CLIP, 里面提到CLIP最大的贡献在于打破了固定类…
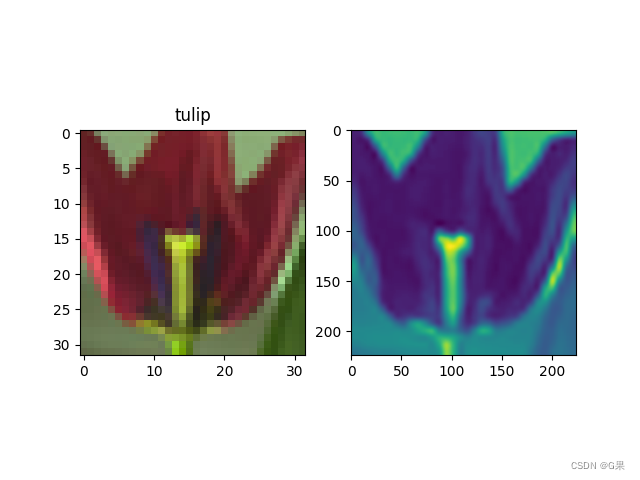
小白看CLIP代码解析
CLIP代码解析 CLIP演示代码(以cifar100举例)补充11. 为什么选用100*image_feature?2. 为什么使用L2规范点积,而不直接使用点积? cifar100的所有类别model.encode_image >> VisionTransformer补充21. 为什么加入c…
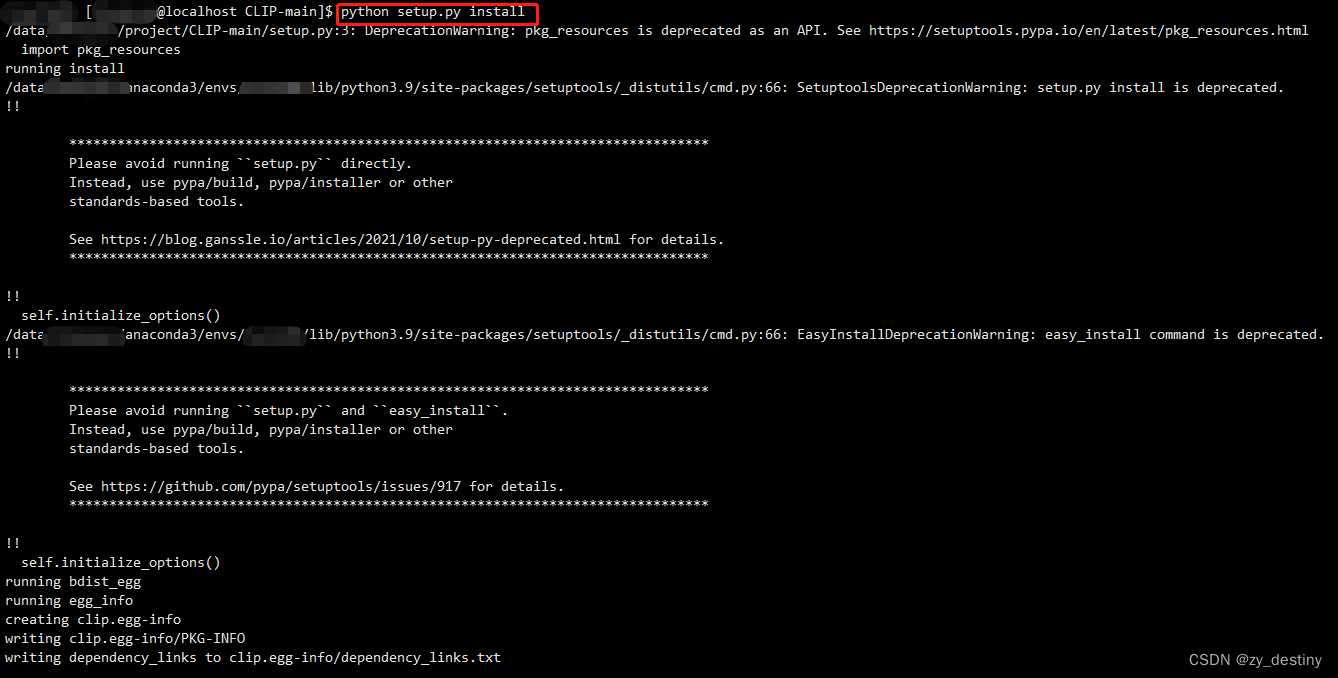
【git】pip install git+https://github.com/xxx/xxx替换成本地下载编译安装解决网络超时问题
目录
🌑🌑 背景
🌒 🌒作用
🌔🌔 问题
🌔🌔解决方案
🌙方法一
🌙方法二
🌝🌝我的解决方案
整理不易,欢迎一键三连…

【计算机视觉】使用 notebook 展示如何下载和运行 CLIP models,计算图片和文本相似度,实现 zero-shot 图片分类
文章目录 一、CLIP 模型二、准备三、加载模型四、查看图片处理器五、文本分词六、输入图片和文本,并可视化七、将图片和文字 encode 生成特征八、计算 cosine 相似度九、零样本进行图片分类十、编写函数进行图片分类十一、测试自己的函数十二、编写函数对多图片进行…
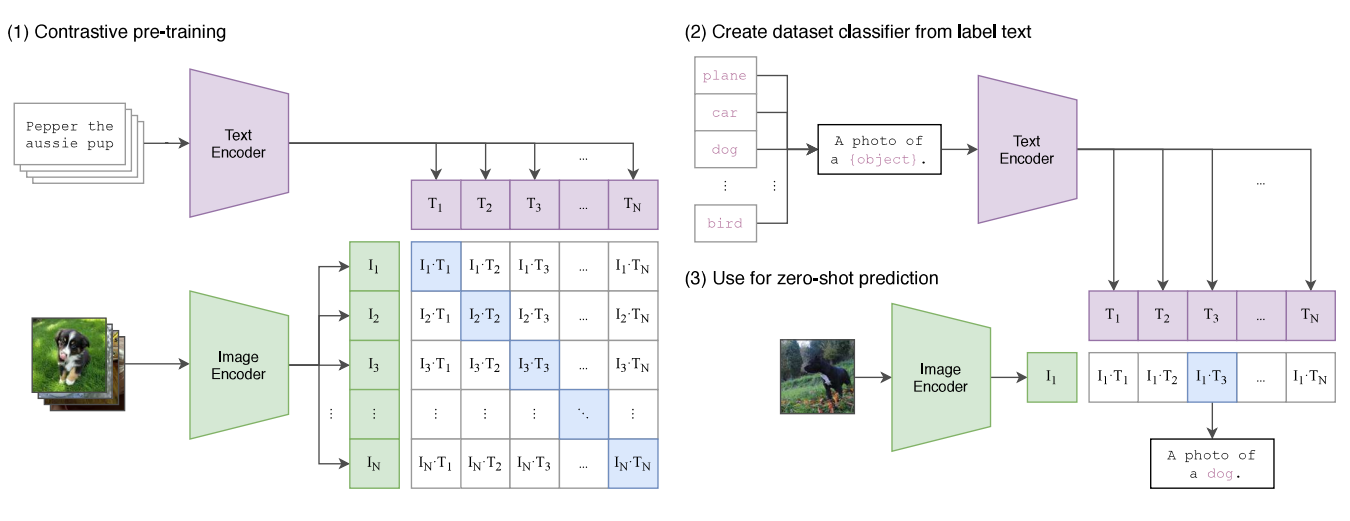
【计算机视觉】CLIP:语言-图像表示之间的桥梁
文章目录一、前言二、架构三、应用3.1 图像分类3.2 图像描述3.3 文本到图像四、总结一、前言
最近GPT4的火爆覆盖了一个新闻:midjourney v5发布,DALLE2,midjourney都可以从文本中生成图像,这种模型要求人工智能同时理解语言和图像…
【深度学习】clip-interrogator clip docker 容器启动过程
文章目录 dockerfile备忘ENTRYPOINT ["bash", "/app/startProject.sh"]常用docker指令web服务脚本访问接口文件 给一张图片,输出图片描述。
dockerfile备忘
只有从dockerfile制作的镜像才有分层结构,加速传输,故第一步…
stable diffusion安装踩坑之clip安装、git报错
clip本地安装环境链接问题
本节主要记录一下在windows安装stable diffusion时,clip脚本安装不上,本地安装时如何链接到当前库的问题
首先,在脚本安装clip不成功时,脚本会输出一个commend指令,复制到浏览器就可以很快…
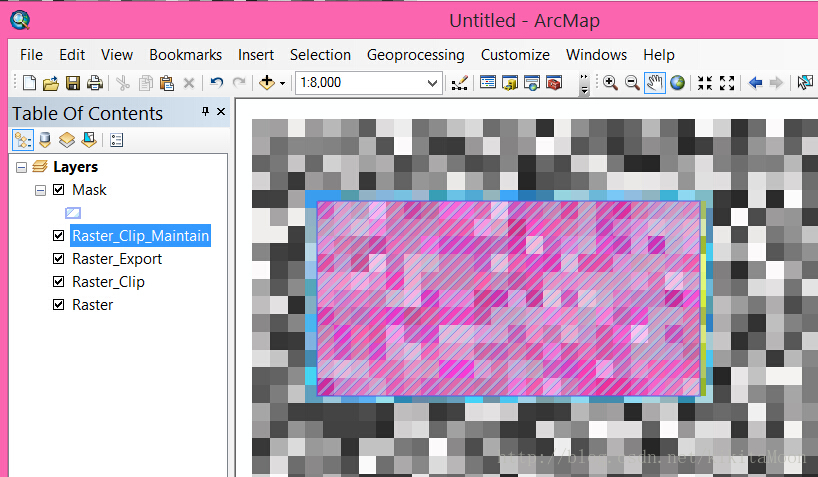
使用矢量面裁剪栅格数据的对齐问题
最近凑巧有几个比较多的栅格裁剪问题,整理如下: 我们只有由于栅格与矢量数据的存储模型不相同,这就导致栅格数据的像元无法与矢量数据的点等同,从而导致裁切后的对齐问题,放大数据我们就能发现,如下图可以说…